Preparation of biodiversity and predictor data
Martin Jung
2026-06-15
Source:vignettes/articles/01_data_preparationhelpers.Rmd
01_data_preparationhelpers.RmdThe first step with any species distribution modelling (SDM) is to
collect and prepare the necessary input data and parameters for the
modelling. Predictors or (environmental) covariates need to be acquired,
in many cases formatted, for example through masking and reprojections,
and standardized. Similarly, Biodiversity data are usually collected
through independent field survey or from available databases such as
GBIF. In particular for the ibis.iSDM package it can
furthermore be useful to collect any other information available for a
biodiversity feature (e.g. species, habitat, …) in question. Such as for
example broad delineation of an expert range or parameters related to
the habitat preference of a species.
Preparing input data for the ibis.iSDM package requires
a modest understanding of modern geospatial R-packages, such as
sf, terra and stars. If such
knowledge is not existing, it is advised to consult a search engine.
Particularly highlighted is the free Geocomputation with R book. Many
unexpected errors or patterns when using the package can usually be
tracked down to data preparation.
# Load the package
library(ibis.iSDM)
library(terra)
library(sf)
# Don't print out as many messages
options("ibis.setupmessages" = FALSE)Preparing and altering biodiversity data
SDM approaches require observation biodiversity data, typically in the form of presence-only or presence-absence data, which can be available in a range of different formats from points to polygons.
There are a range of existing
tools that assist modellers in preparing and cleaning input data
(for instance of biases). This vignette does not intend to give an
overview of the options. Rather it highlights the few functions that
have been created specifically for the ibis.iSDM package
and that might help in some situations.
Adding pseudo-absence points to presence-only data
Although in the philosophy of the ibis.iSDM package it
is advisable to use presence-only models in a Poisson point process
modelling framework (‘poipo’ modelling functions that use background
points (see Warton and
Sheperd 2010). Yet, a good case can also be made to instead add
pseudo-absence points to existing presence-only data. This allows the
use of logistic regressions and ‘poipa’ methods in
ibis.iSDM which are generally easier to interpret (response
scale from 0 to 1) and also faster to fit as model.
## Lets load some testing data from the package
# Background layer
background <- terra::rast(system.file("extdata/europegrid_50km.tif",package = "ibis.iSDM", mustWork = TRUE))
# Load virtual species points
virtual_species <- sf::st_read(system.file("extdata/input_data.gpkg",package = "ibis.iSDM", mustWork = TRUE), "points",quiet = TRUE)
# Add a range
virtual_range <- sf::st_read(system.file('extdata/input_data.gpkg', package='ibis.iSDM'), 'range', quiet = TRUE)Adding pseudo-absence data in the ibis.iSDM package
works by first specifying a Pseudoabsence options object that
contains parameters how many and where pseudo-absences are to be
sampled. The respective function for this is called
pseudoabs_settings(). Further details on the available
options here (there are many) can be found in the help file. By default
the packages uses a random sampling of absence points and the settings
for this can be queried here
ibis_options()$ibis.pseudoabsence.
After such options have been defined, pseudo-absence data can be
added to any point dataset via add_pseudoabsence().
Example:
# Define new settings for sampling points outside the minimum convex polygon of
# the known presence data
abs <- pseudoabs_settings(background = background,
nrpoints = 1000, # Sample 1000 points
method = "mcp", # Option for minimum convex polygon
inside = FALSE # Sample exclusively outside
)
print( abs ) # See object, check abs$data for the options
# Now add to the point data
point1 <- add_pseudoabsence(virtual_species,
# Point to the column with the presence information
field_occurrence = 'Observed',
settings = abs)
plot(point1['Observed'])
# --- #
# Another option sampling inside the range, but biased by a bias layer
bias <- terra::rast(system.file("extdata/predictors/hmi_mean_50km.tif",
package = "ibis.iSDM", mustWork = TRUE))
abs <- pseudoabs_settings(background = background,
nrpoints = 100, # Sample 100 points
method = "range", # Define range as method
inside = TRUE, # Sample exclusively inside
layer = virtual_range, # Define the range
bias = bias # Set a bias layer
)
# Add again to the point data
point2 <- add_pseudoabsence(virtual_species,
# Point to the column with the presence information
field_occurrence = 'Observed',
settings = abs)
plot(point2['Observed'])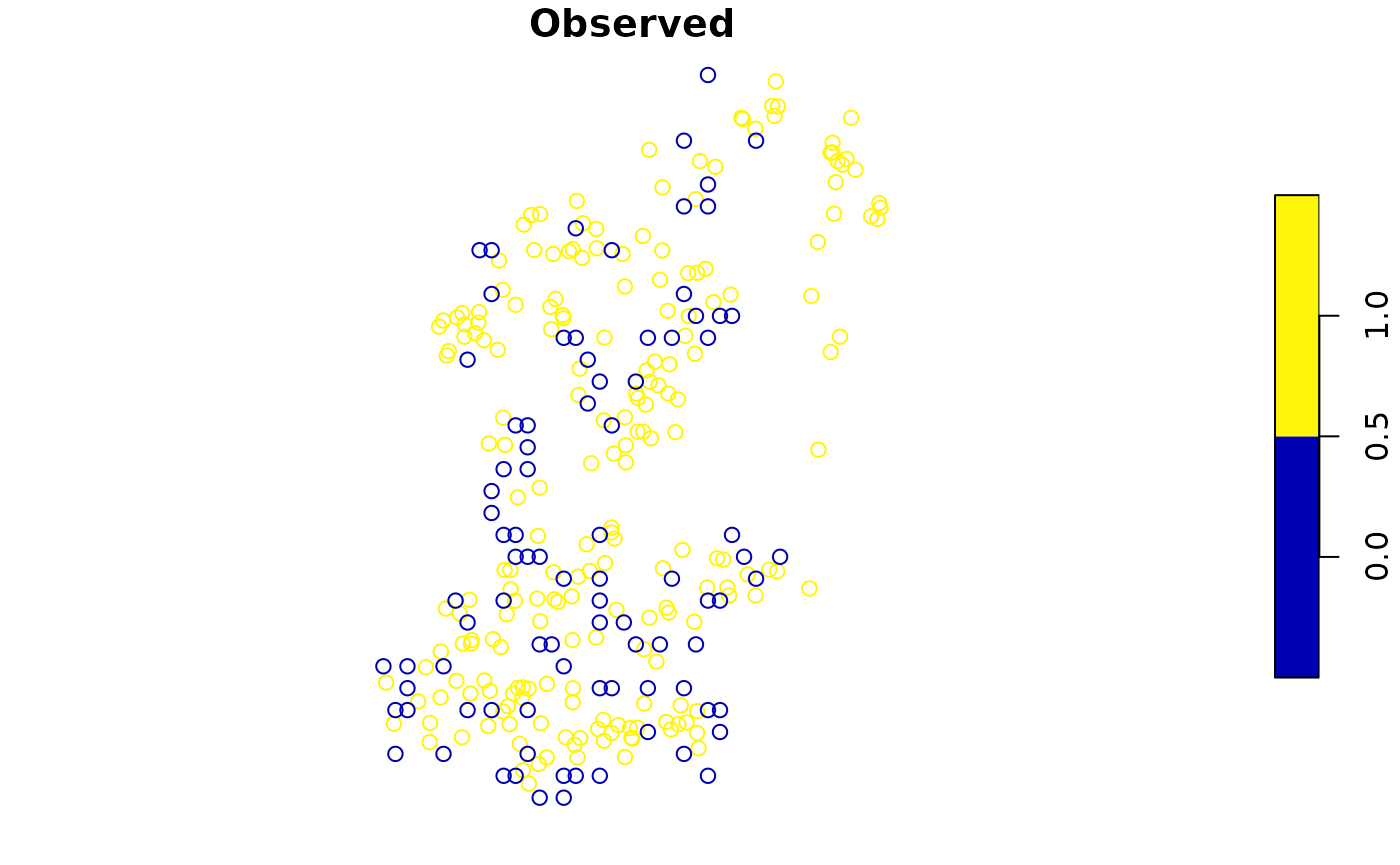
Thinning observations
Many presence-only records are often spatially highly biased with varying observational processes resulting in quite clustered point observations. For example, urban areas and natural sites near them are considerably more often frequented by citizens observed wildlife than sites in remote areas. Particular for Poisson process models that can be problematic as such models critically assume - without accounting for it - that the observational process is homogeneous in space.
Thinning observations is a method to remove point observations from
areas that have been “oversampled”. Critically however it does only
remove points from grid cells of a provided background where this is the
case and never removes the entire grid cell fully. It can also be
beneficial for model convergence and modelling speed, as particular for
well-sampled species (e.g. the common blackbird Turdus merula)
there are diminishing returns of fitting a SDM with like 1 million
presence-only points instead of just 20000 well separated ones. The
ibis.iSDM package has its own implementation for spatial
thinning, but one can also refer to Aiello-Lammens et al. for
an alternative implementation and rationale for thinning.
Thinning needs to be conducted with care as it effectively discards data!
## We use the data loaded in above
plot(virtual_species['Observed'], main = "Original data")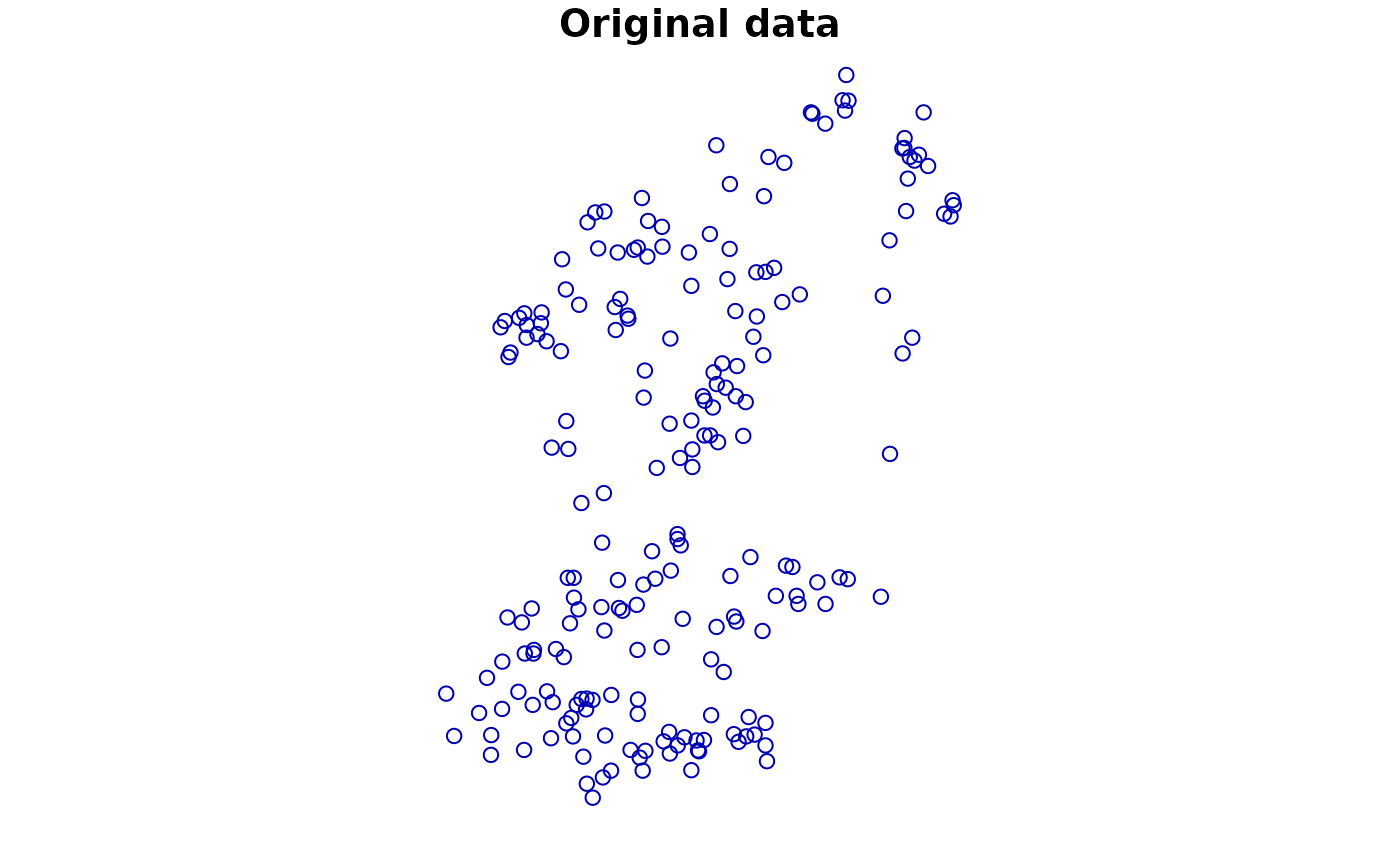
# Random thinning. Note the messages of number of thinned points
point1 <- thin_observations(data = virtual_species,
background = background,
method = 'random',
remainpoints = 1 # Retain at minimum one point per grid cell!
)
#> (random) thinning completed!
#> Original number of records: 208
#> Number of retained records: 175
plot(point1['Observed'], main = "Random thinning")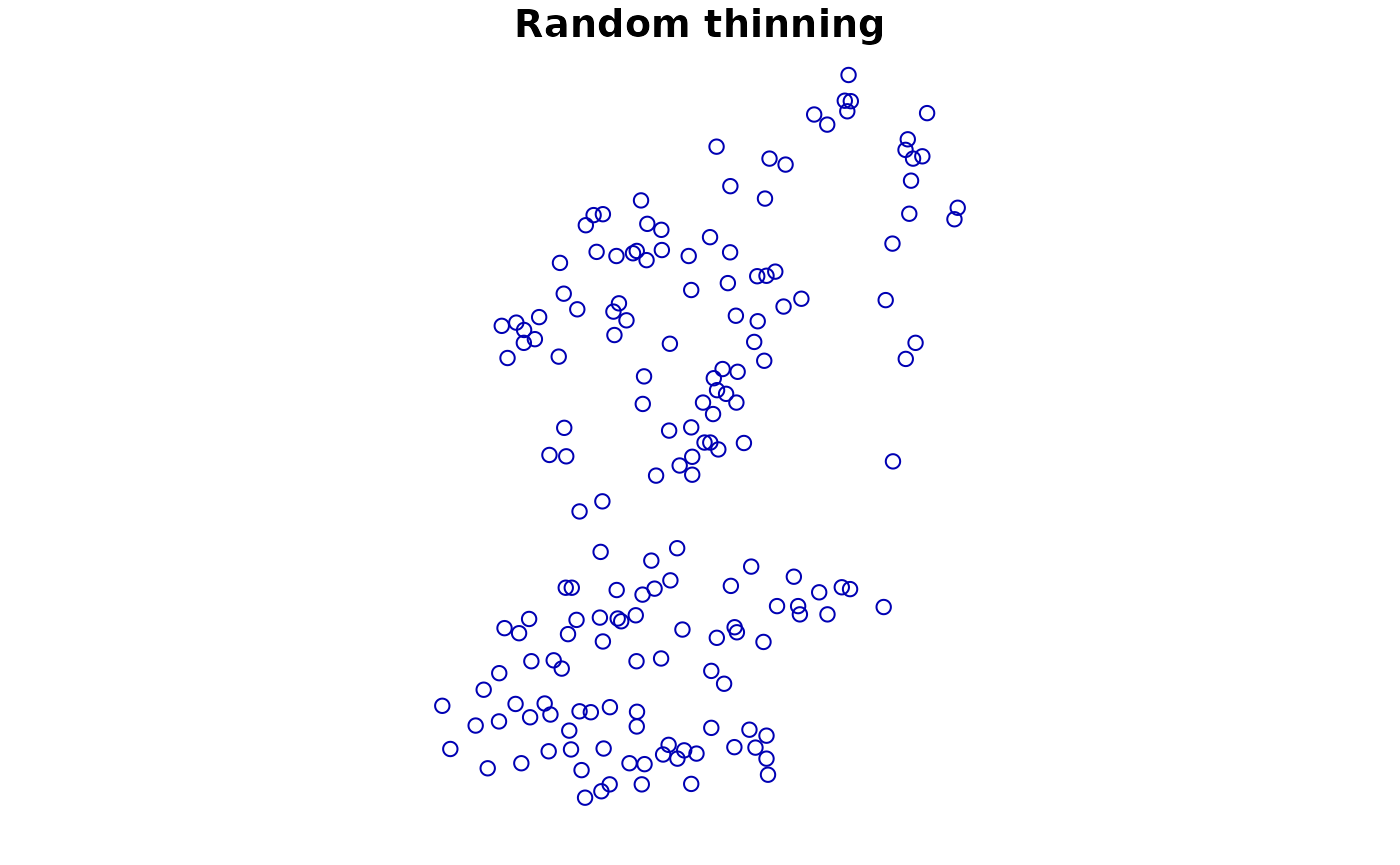
# Another way: Use environmental thinning to retain enough points
# across the niche defined by a set of covariates
covariates <- terra::rast(list.files(system.file("extdata/predictors/", package = "ibis.iSDM", mustWork = TRUE), "*.tif",full.names = TRUE))
point2 <- thin_observations(data = virtual_species,
background = background,
env = covariates,
method = 'environmental',
remainpoints = 5 # Retain at minimum five points!
)
#> (environmental) thinning completed!
#> Original number of records: 208
#> Number of retained records: 26
plot(point2['Observed'], main = "Environmentally stratified data")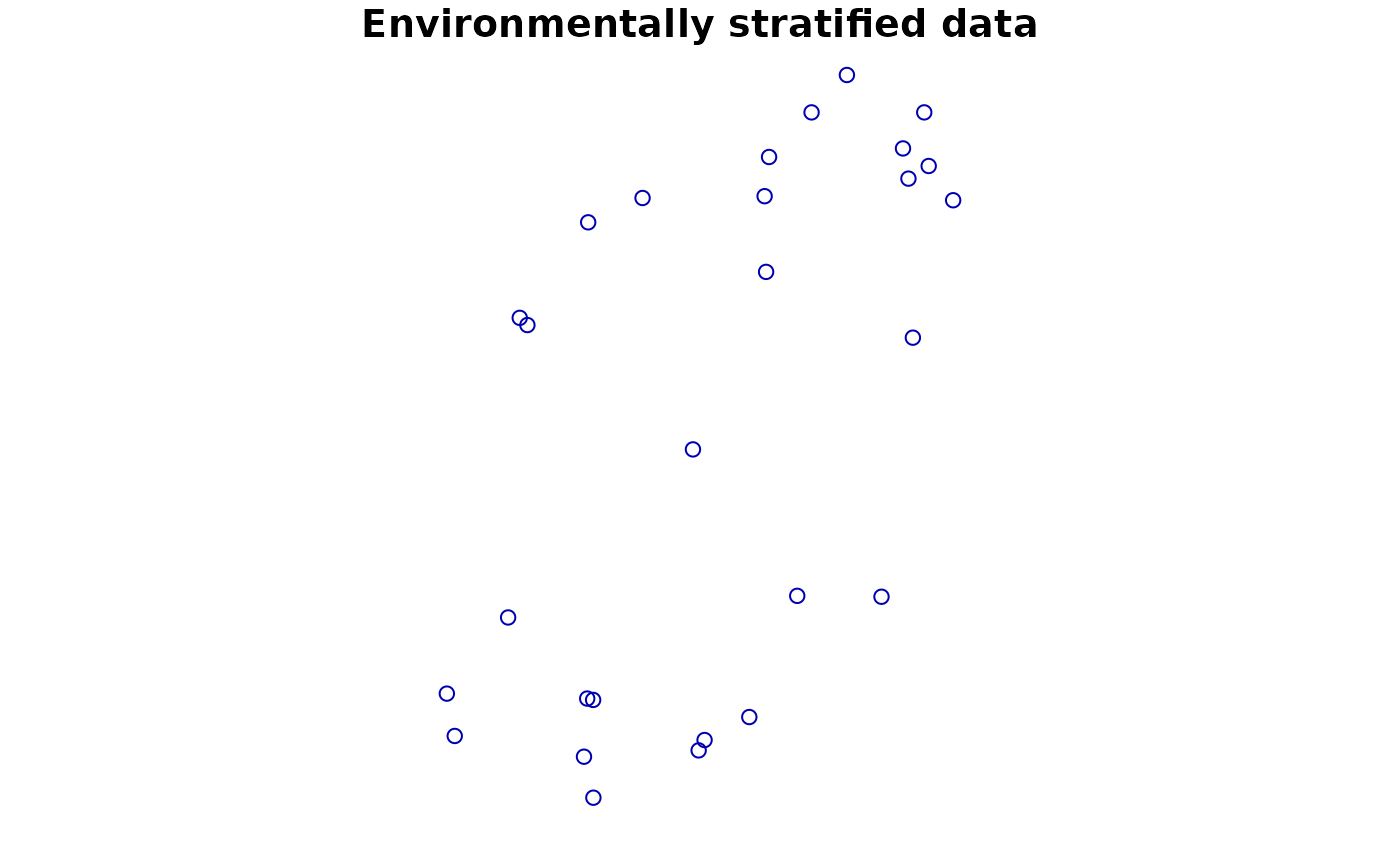
Preparing and altering predictor data
In order to be used for species distribution modelling all predictors
need to be provided in a common extent, grain size and geographic
projections. They need to align with the provided background extent to
distribution() and should ideally not contain no missing
data. If there are missing data, the package will check and remove
during model fitting points that fall into any grid cells with missing
data.
The ibis.iSDM package has a number of convenience
functions to modify input predictors. These functions rather provide
nuance(s) and variation to the modelling process, rather than preparing
the input data (which needs to be undertaken using the
terra package).
# Load some test covariates
predictors <- terra::rast(list.files(system.file("extdata/predictors/", package = "ibis.iSDM", mustWork = TRUE), "*.tif",full.names = TRUE))Transforming predictors
For better model convergence it usually makes sense to bring all
predictors to a common unit, for example by normalizing or scaling them.
The ibis.iSDM package has a convenience function that can
be applied to any terra ‘SpatRaster’ object.
NOTE: This functionality is also available directly in
add_predictors() as parameter!
# Let's take a simple layer for an example
layer <- predictors$bio19_mean_50km
# Transform it in various way
new1 <- predictor_transform(layer, option = "norm")
new2 <- predictor_transform(layer, option = "scale")
new <- c(layer, new1, new2)
names(new) <- c("original", "normalized", "scaled")
terra::plot( new )![]()
# Another common use case is to windsorize a layer, for example by removing
# top outliers from a prediction.
# Here the values are capped to a defined percentile
new3 <- predictor_transform(layer, option = "windsor",
# Clamp the upper values to the 90% percentile
windsor_props = c(0,.9))
new <- c(layer, new3)
names(new) <- c("original", "windsorized")
terra::plot( new )![]()
Other options for transformation are also available and are listed in the methods file.
Derivates of predictors
A simple linear SDM (e.g. engine_glmnet()) includes the
predictors as such and thus assumes that any increase in the response
variable follows a linear relationship with the covariate. However,
reality is not always that simple and usually it can be assumed that
many relationships are highly non-linear or otherwise complex.
A standard way to introduce non-linearities to a linear algorithm is
to create derivates of predictors, such as for example a quadratic
transformation of temperature. The ibis.iSDM package has a
convenience function that can be applied to any terra
‘SpatRaster’ object to create such additional derivates for a model.
Note that this creates (in some cases substantial) additional
predictors.
NOTE: This functionality is also available directly in
add_predictors() as parameter!
# Let's take a simple layer for an example
layer <- predictors$ndvi_mean_50km
# Make a quadratic transformation
new1 <- predictor_derivate(layer, option = "quadratic")
new <- c(layer, new1)
names(new) <- c("original", "quadratic")
terra::plot( new )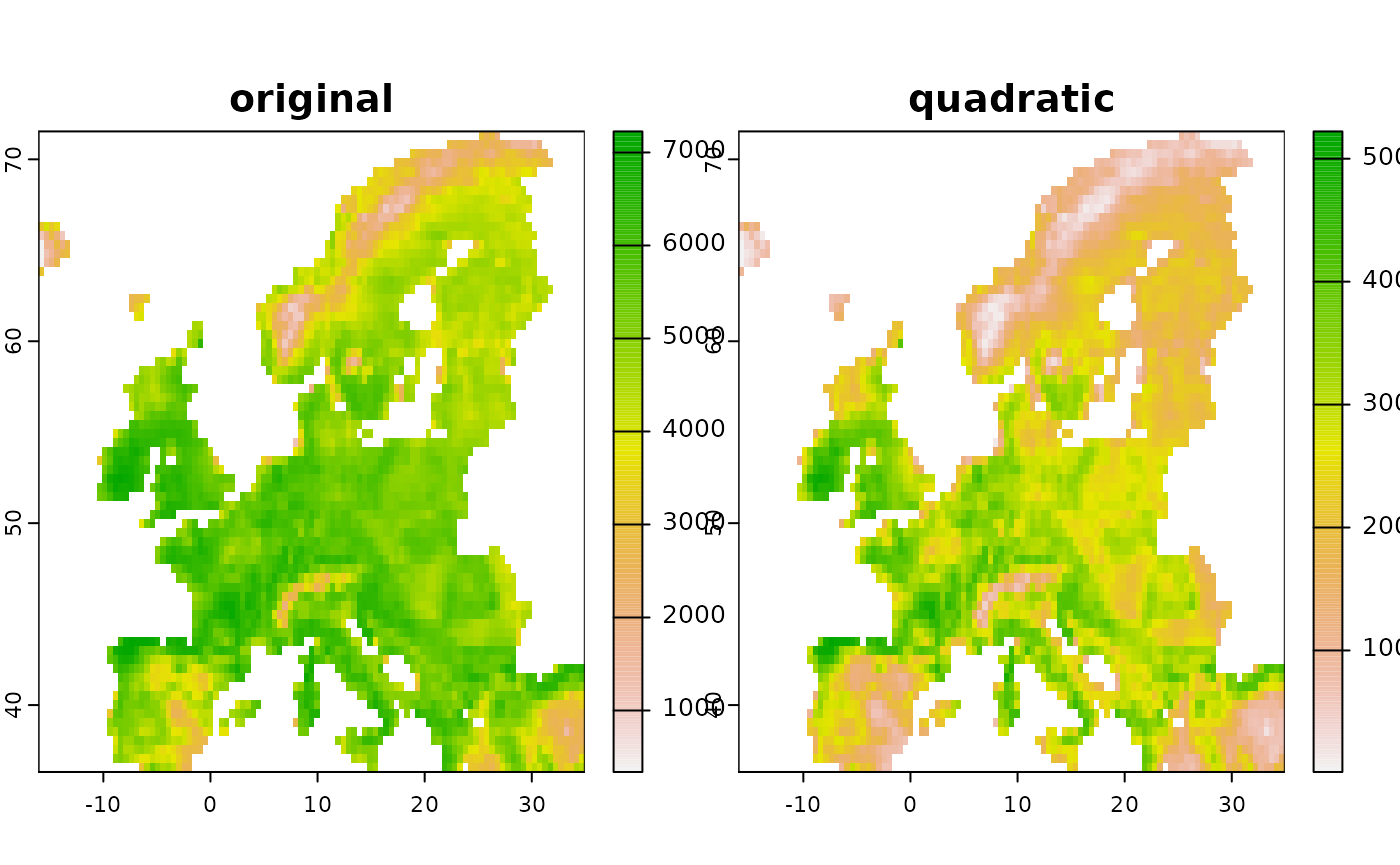
# Create some hinge transformations
new2 <- predictor_derivate(layer, option = "hinge",
# The number is controlled by the number of knots
nknots = 4
)
terra::plot( new2 )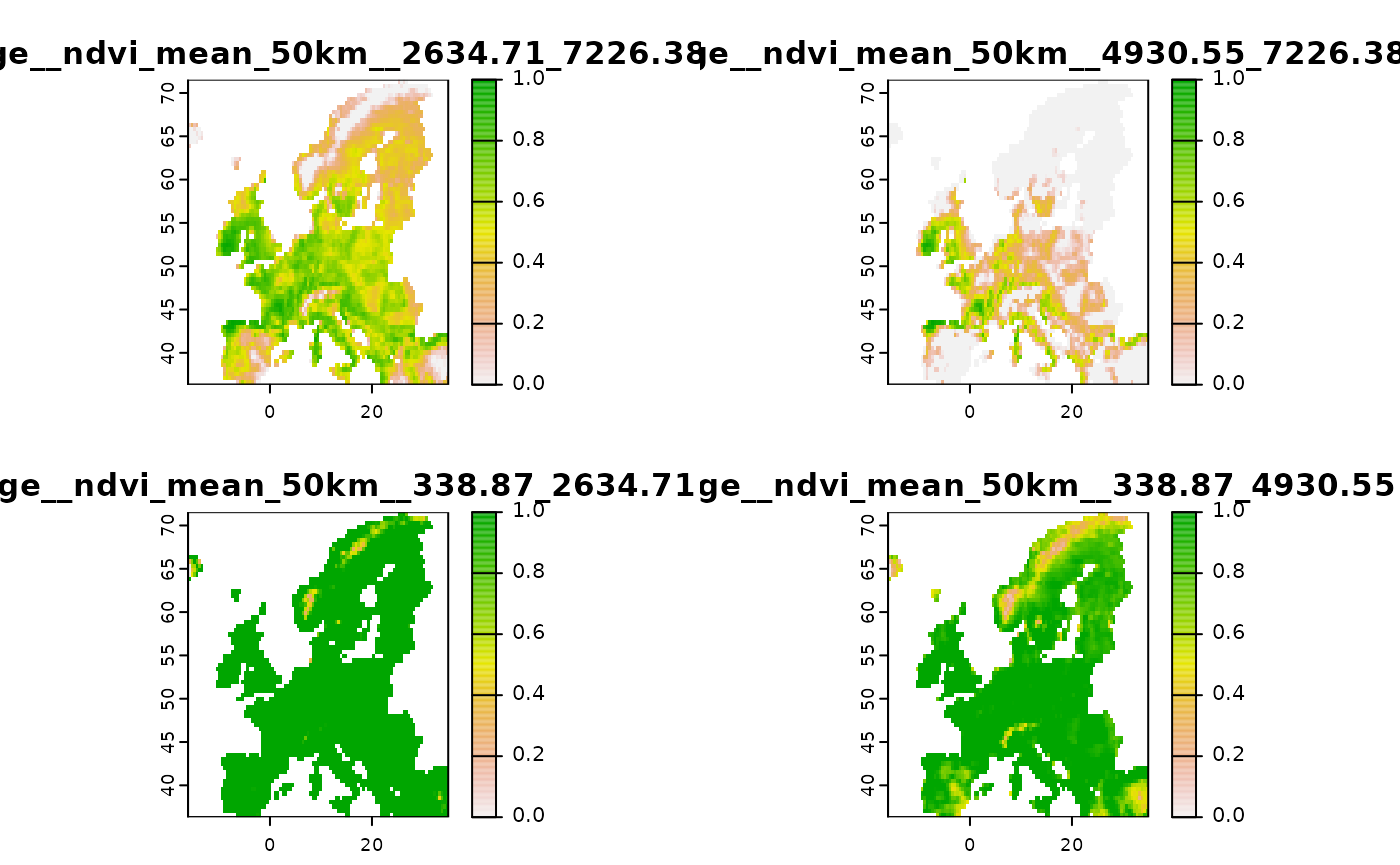
# What does this do precisely?
# Lets check
df <- data.frame( ndvi = terra::values(layer),
terra::values(new2))
plot(df$ndvi_mean_50km, df[,2], ylab = "First hinge of ndvi", xlab = "NDVI")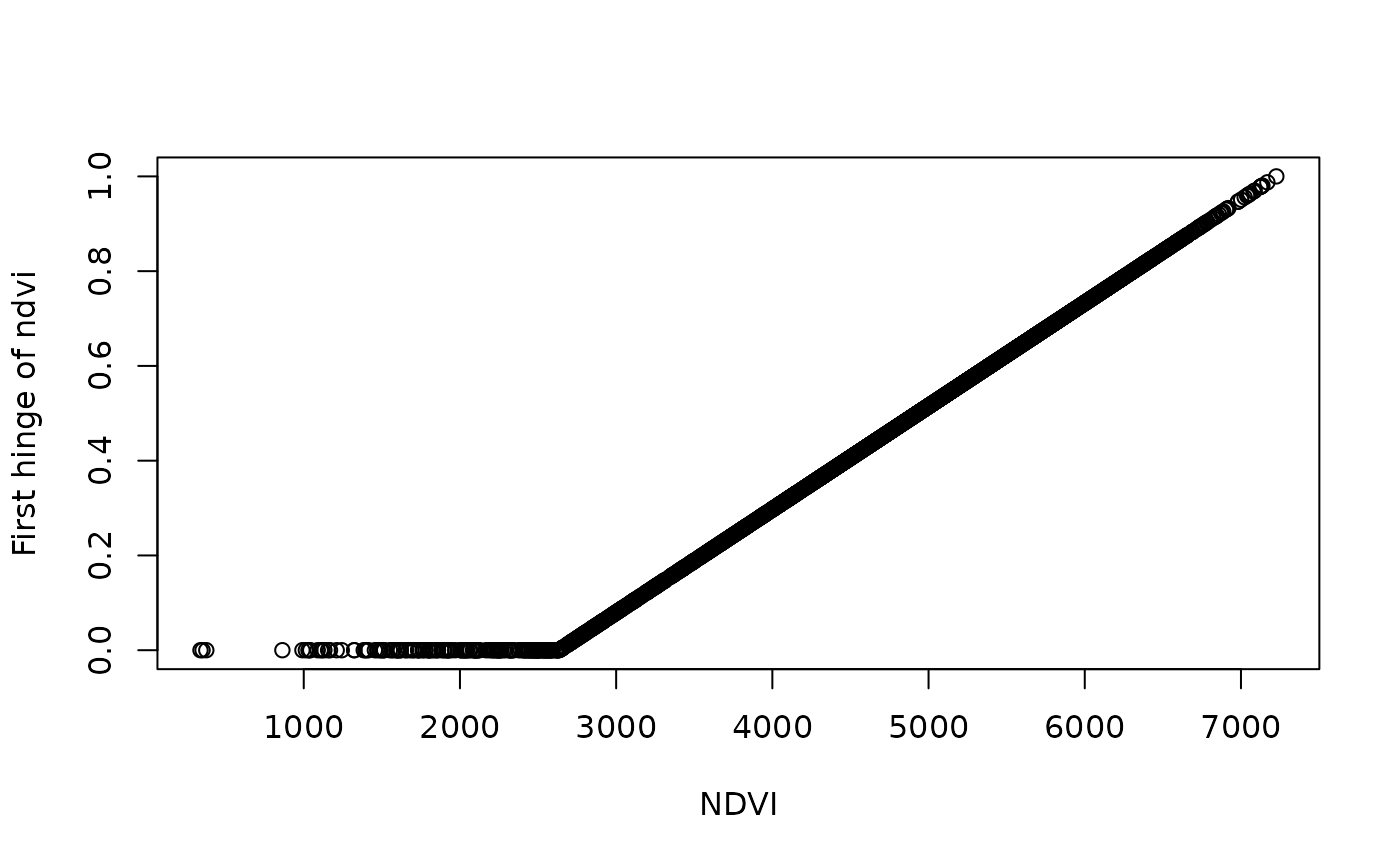
plot(df$ndvi_mean_50km, df[,3], ylab = "Second hinge of ndvi",xlab = "NDVI")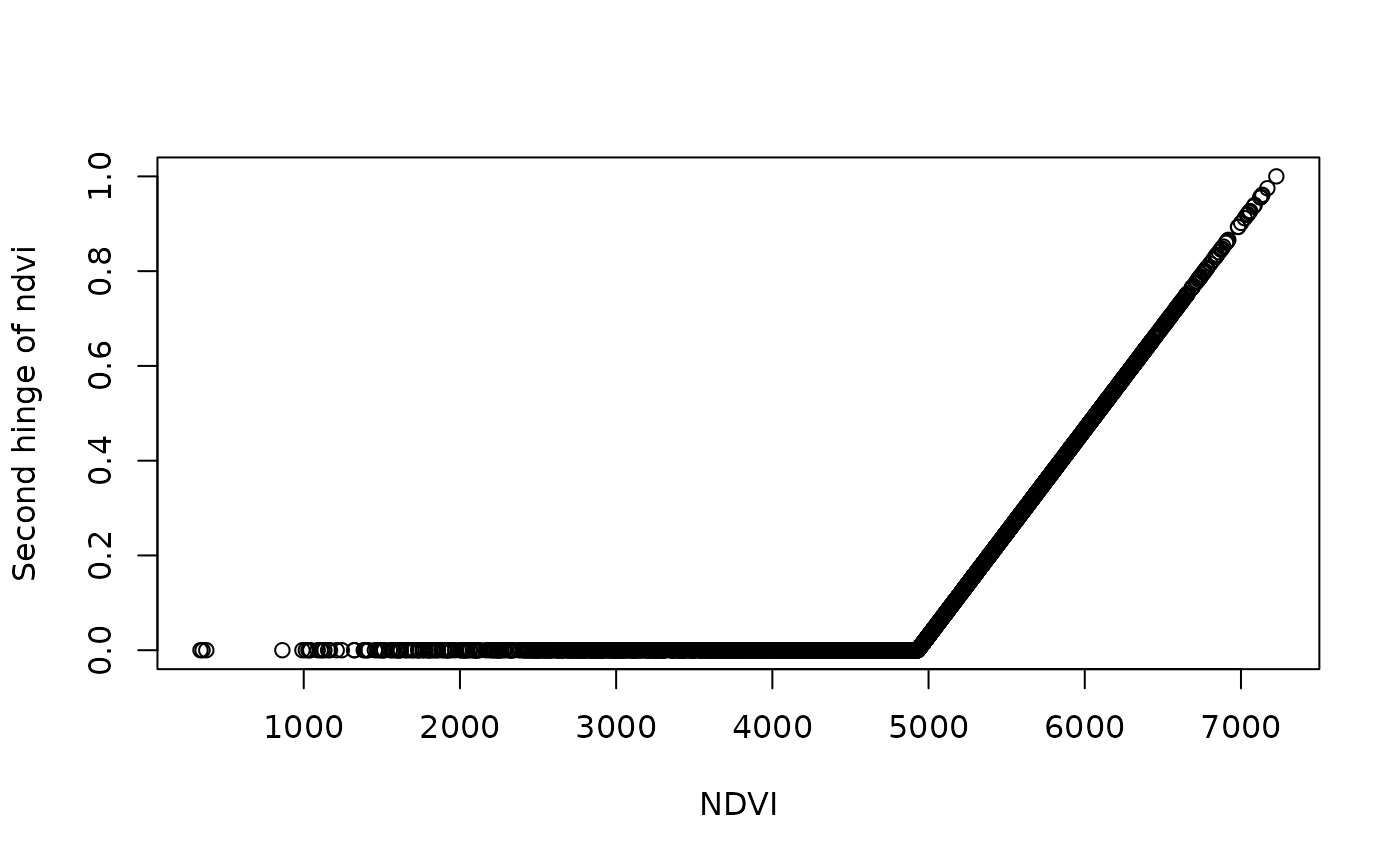
plot(df$ndvi_mean_50km, df[,4], ylab = "Third hinge of ndvi", xlab = "NDVI")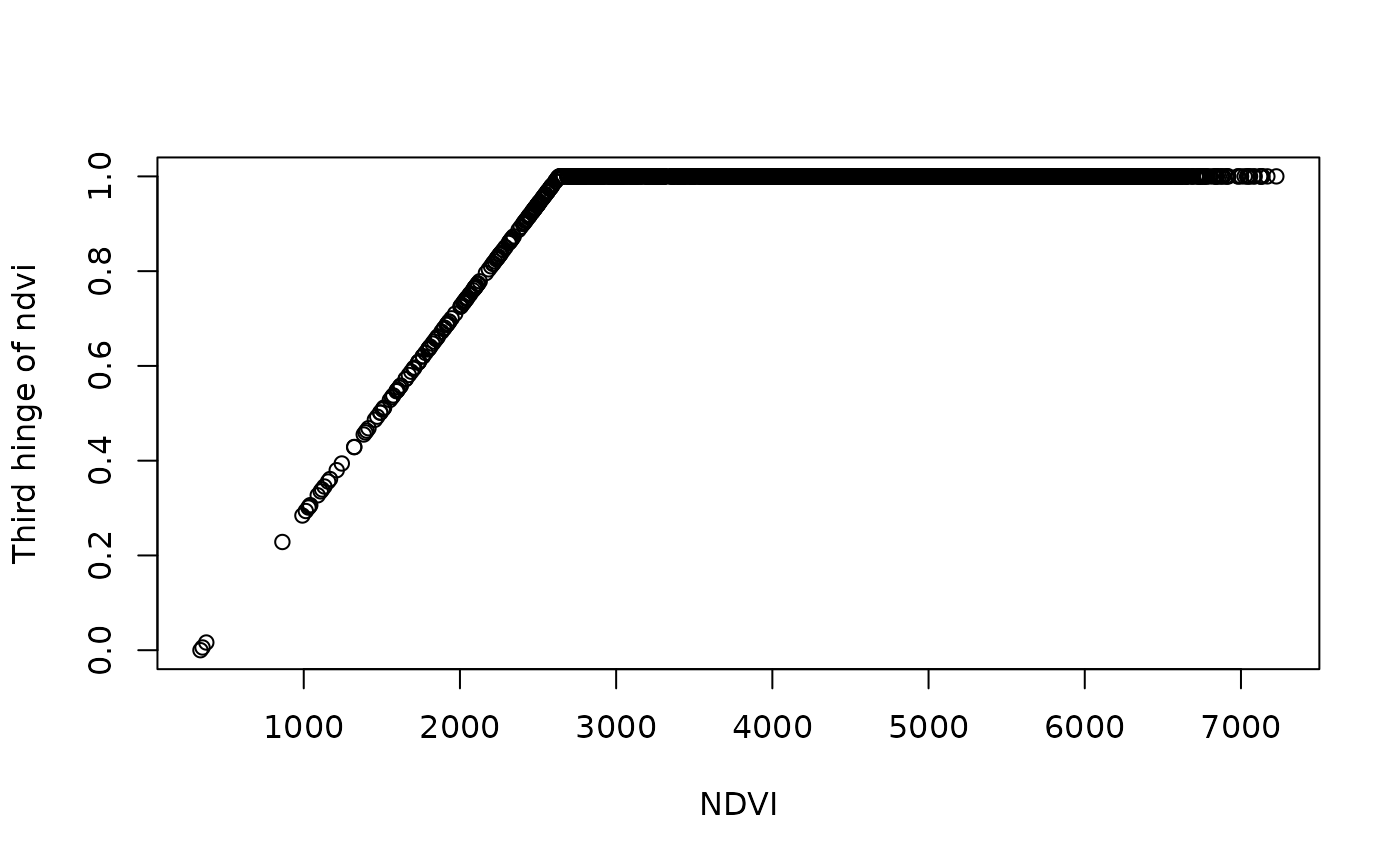
plot(df$ndvi_mean_50km, df[,5], ylab = "Fourth hinge of ndvi",xlab = "NDVI")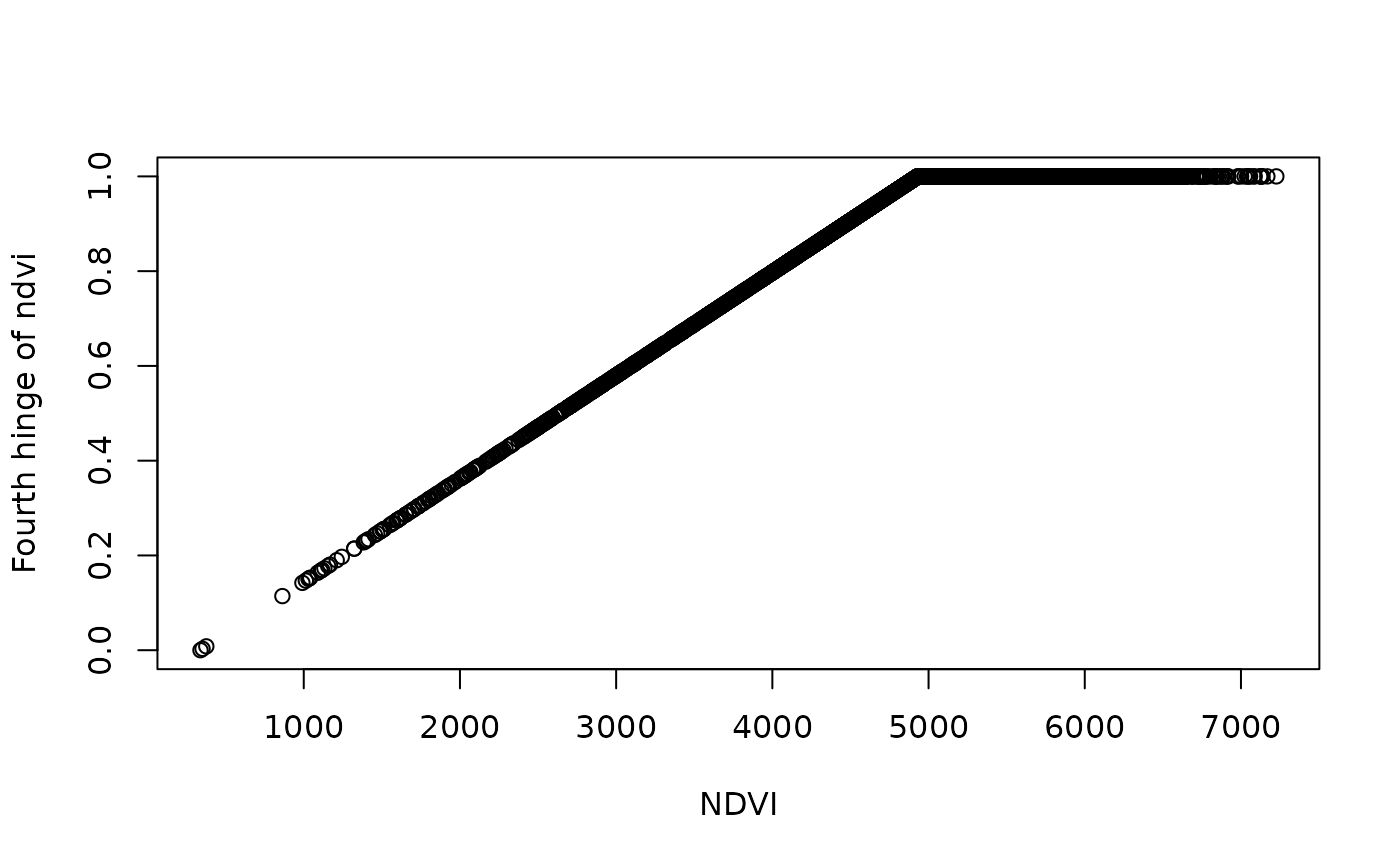
More fine-tuned control can also be achieved by creating specific interactions among variables, for example if one expects climate to interact with forest cover.
# Create interacting variables
new <- predictor_derivate(predictors,option = "interaction",
int_variables = c("bio01_mean_50km", "CLC3_312_mean_50km"))
plot(new, main = "Interaction variable")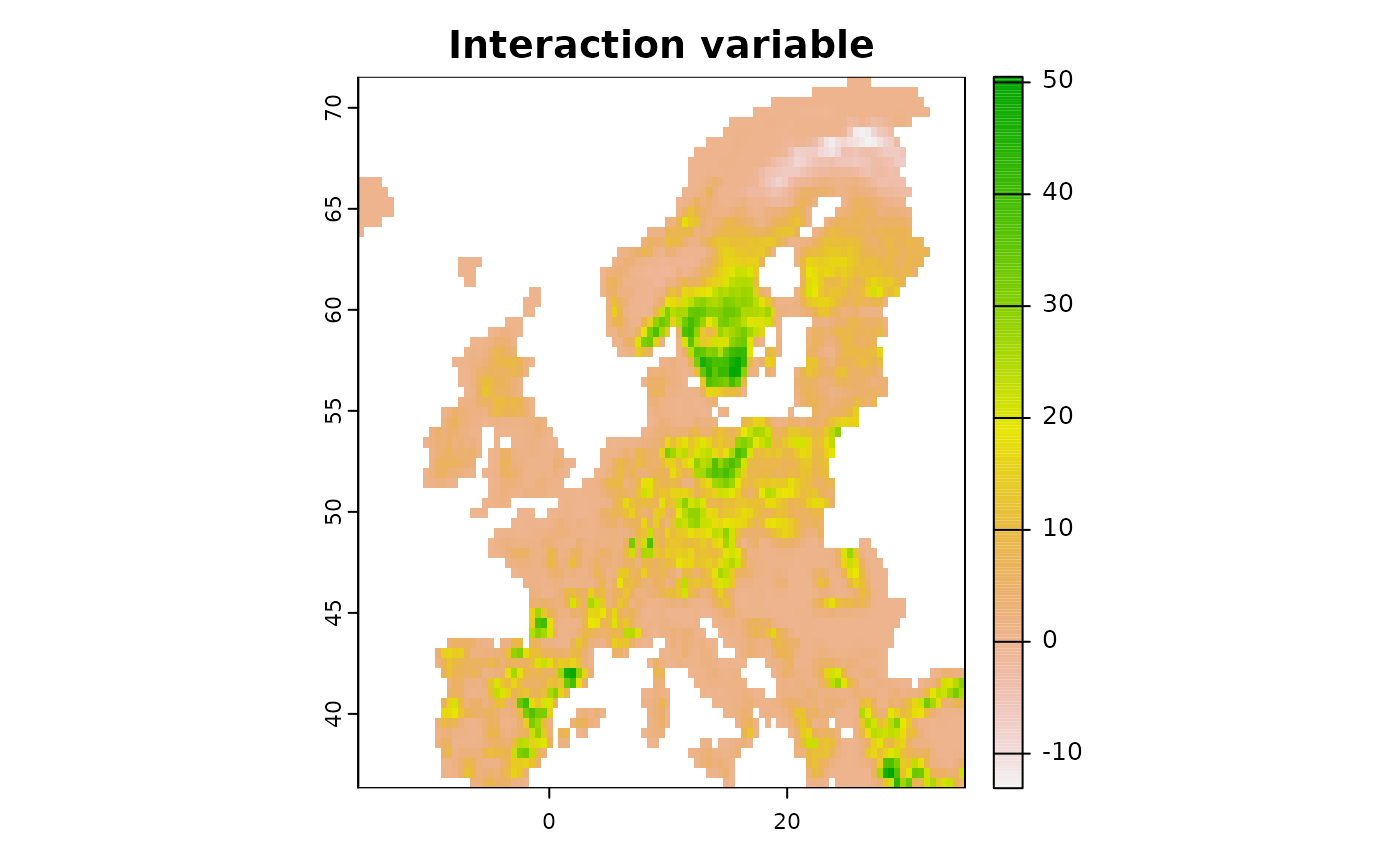
Spatially summarize predictor data
Occasionally predictor values in a certain region might only be
available for a few grid cells or be associated with considerable
uncertainty. Similarly, gridded layers can also be modified to test
stylistic scenarios (for example what if the entirety of the United
Kingdom would be Forest?). The terra R-package has a range
of functions to aggregate or replace data in gridded layers. In
ibis.iSDM the use of these functions is further eased
through a convenience function for spatial replacement and aggregation.
It is also possible to assign values (for example from a specific zone)
to a different area.
library(terra)
# Load a zonal layer
countries <- terra::rast(system.file("extdata/countries.tif",package = "ibis.iSDM", mustWork = TRUE))
# Get the United Kingdom
uk <- countries == "United Kingdom"
uk[uk==0] <- NA # Set non target
# Get Sweden
sw <- countries == "Sweden"
sw[sw==0] <- NA # Set non target
# Take a Forest class
layer <- predictors$CLC3_312_mean_50km
# Aggregate by countries
layer_co <- predictor_summarize_zones(env = layer,
layer = countries,
fun = 'mean'
)
# Alternative: Replace only values of the UK with the average of the swedish values
layer_uk <- predictor_summarize_zones(env = layer,
layer = sw,
target_layer = uk,
fun = 'mean'
)
# Show the difference
terra::plot(c(layer, layer_co, layer_uk),
main = c("original", "aggregated", "UK replaced"))Homogenize missing data among predictors
As mentioned above, during model training covariates will be
extracted for each biodiversity observational record. Missing data will
in this case be discarded. For example if 10 predictors are considered
and a single one has a missing value in one grid cell, the grid cell is
considered missing among all other predictors as well. The
ibis.iSDM package has some convenience functions to easily
harmonize and check the extent of missing data in a set of predictors
which can be convenient for assessing errors during data
preparation.
# Make a subset of all predictors to show the concept
layers <- subset(predictors, c("aspect_mean_50km",
"CLC3_312_mean_50km",
"elevation_mean_50km"))
# All these layers have identical data coverage.
# Now add missing data in one of the layers for testing
layers$CLC3_312_mean_50km[sample(1:ncell(layers), 1000)] <- NA
# Harmonize the predictors
new <- predictor_homogenize_na(env = layers)
# Now all the predictors have identical coverage of NA values
terra::plot(new)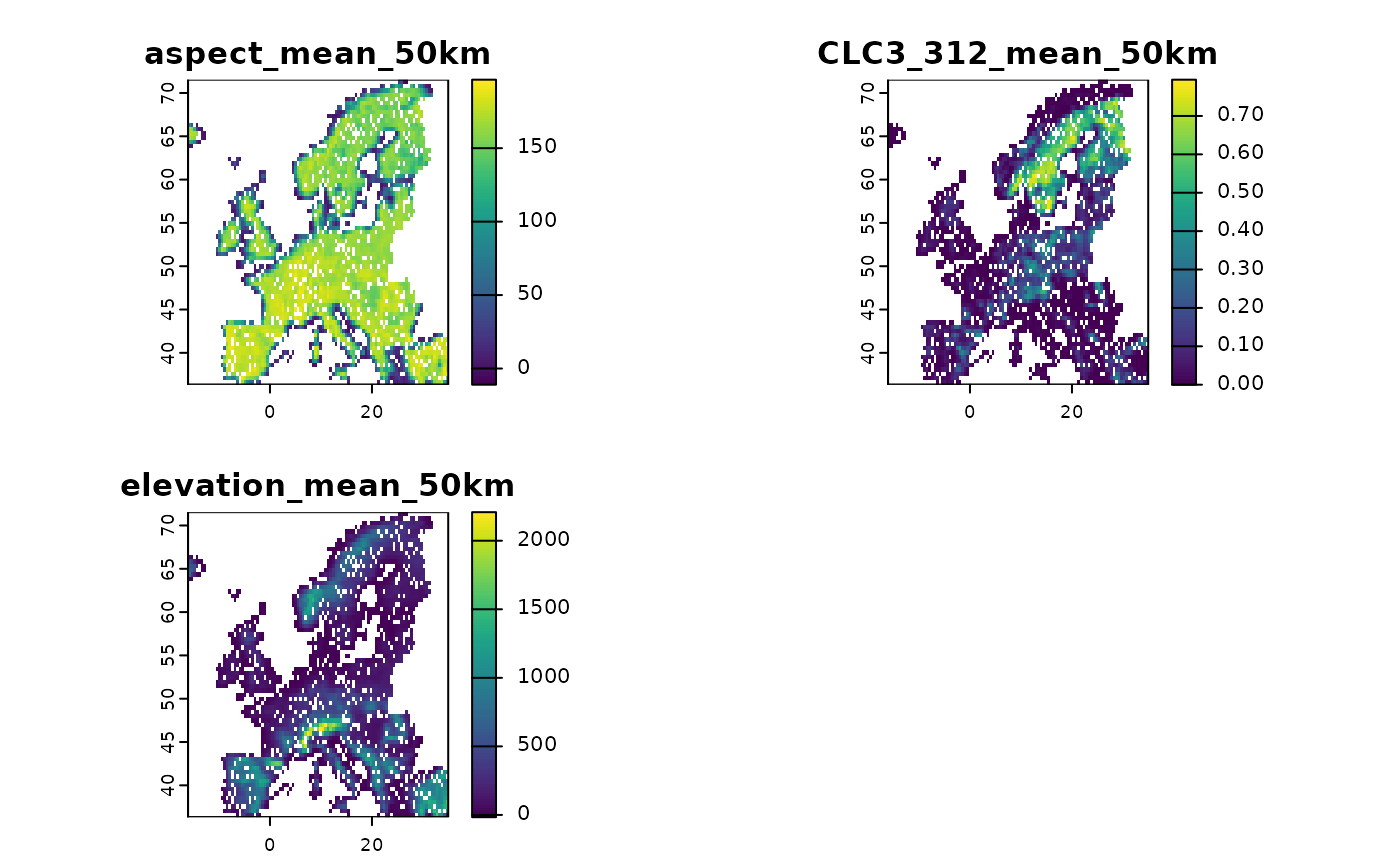

Preparing and altering future scenario data
Creating in scenarios in R requires input predictors to be formatted
in a different format than before. The ibis.iSDM package here
makes extensive use of stars to prepare and load
multi-dimensional data.
One common issue here that predictors are not in the requested time dimension. For example climate data might only be available at a decadal scale (e.g. 2020, 2030, 2040), yet predictions are often required on a finer temporal grain.
For this purpose the ibis.iSDM contains a dedicated function
(interpolate_gaps()), that can also be directly called
within project().
# Load some stars rasters
ll <- list.files(system.file('extdata/predictors_presfuture/',
package = 'ibis.iSDM',
mustWork = TRUE),full.names = TRUE)
# Load the same files future ones
suppressWarnings(
pred_future <- stars::read_stars(ll) |> dplyr::slice('Time', seq(1, 86, by = 10))
)
sf::st_crs(pred_future) <- sf::st_crs(4326)
# The predictors are here only available every 10 years
stars::st_get_dimension_values(pred_future, 3)
#> [1] "2015-01-01" "2025-01-01" "2035-01-01" "2045-01-01" "2055-01-01"
#> [6] "2065-01-01" "2075-01-01" "2085-01-01" "2095-01-01"
# --- #
# The ibis.iSDM contains here a function to make interpolation among timesteps,
# thus filling gaps in between.
# As an example,
# Here we make a temporal interpolation to create an annual time series
new <- interpolate_gaps(pred_future, date_interpolation = "annual")
stars::st_get_dimension_values(new, 3)
#> [1] "2015-07-02" "2016-07-02" "2017-07-02" "2018-07-02" "2019-07-02"
#> [6] "2020-07-02" "2021-07-02" "2022-07-02" "2023-07-02" "2024-07-02"
#> [11] "2025-07-02" "2026-07-02" "2027-07-02" "2028-07-02" "2029-07-02"
#> [16] "2030-07-02" "2031-07-02" "2032-07-02" "2033-07-02" "2034-07-02"
#> [21] "2035-07-02" "2036-07-02" "2037-07-02" "2038-07-02" "2039-07-02"
#> [26] "2040-07-02" "2041-07-02" "2042-07-02" "2043-07-02" "2044-07-02"
#> [31] "2045-07-02" "2046-07-02" "2047-07-02" "2048-07-02" "2049-07-02"
#> [36] "2050-07-02" "2051-07-02" "2052-07-02" "2053-07-02" "2054-07-02"
#> [41] "2055-07-02" "2056-07-02" "2057-07-02" "2058-07-02" "2059-07-02"
#> [46] "2060-07-02" "2061-07-02" "2062-07-02" "2063-07-02" "2064-07-02"
#> [51] "2065-07-02" "2066-07-02" "2067-07-02" "2068-07-02" "2069-07-02"
#> [56] "2070-07-02" "2071-07-02" "2072-07-02" "2073-07-02" "2074-07-02"
#> [61] "2075-07-02" "2076-07-02" "2077-07-02" "2078-07-02" "2079-07-02"
#> [66] "2080-07-02" "2081-07-02" "2082-07-02" "2083-07-02" "2084-07-02"
#> [71] "2085-07-02" "2086-07-02" "2087-07-02" "2088-07-02" "2089-07-02"
#> [76] "2090-07-02" "2091-07-02" "2092-07-02" "2093-07-02" "2094-07-02"
#> [81] "2095-07-02"Derivates of scenario predictors
As with SpatRaster covariates, it is also possible to
create transformed or derivate versions of scenario predictors through
the same helper function.
# Load some stars rasters
ll <- list.files(system.file('extdata/predictors_presfuture/',
package = 'ibis.iSDM',
mustWork = TRUE),full.names = TRUE)
# Load the same files future ones
suppressWarnings(
pred_future <- stars::read_stars(ll[1:3]) |> dplyr::slice('Time', seq(1, 86, by = 10))
)
sf::st_crs(pred_future) <- sf::st_crs(4326)
# Scale
new <- predictor_transform(pred_future, option = "scale")
# Add quadratic transformed variables to the scenario object
new2 <- predictor_derivate(pred_future, option = "quad")
# New variable names
names(new2)
#> [1] "bio01" "bio12" "crops" "quadratic_bio01"
#> [5] "quadratic_bio12" "quadratic_crops"